
Consegue um algoritmo distinguir os heterónimos de Fernando Pessoa?
Se testemunhasse 2020, Álvaro de Campos estaria, certamente, maravilhado e orgulhoso da sua fé nas máquinas. Mas serão elas capazes de o distinguir no meio dos demais?
A pandemia varreu a manada de turistas das ruas de Lisboa. A cidade, já quase permanentemente transfigurada num parque de diversões, parece começar a renascer. Muito antes das fotografias de Belém encherem páginas de artigos de viagens pelo mundo inteiro, já o bronze da estátua de Fernando Pessoa, sentado na esplanada da Brasileira, refulgia no Chiado - materialização de como a sua obra mudou o rumo da nossa cultura.
Nascido em Lisboa a 13 de Junho de 1888, qual novo santo padroeiro da capital, Fernando Pessoa foi um dos grandes vultos da literatura portuguesa do início do século XX, sendo até hoje aclamado como um dos maiores autores da nossa língua. A sua obra poética mantém-se como grande bastião do programa de Português de 12º ano há décadas e não há quem não se aproveite dos seus versos; alguns deles tão ingloriamente resvalados para lugares-comuns. Quase um século depois, a promessa do progresso traz-nos todos os sonhos do mundo. Se testemunhasse 2020, Álvaro de Campos estaria, certamente, maravilhado e orgulhoso da sua fé nas máquinas. Mas serão elas capazes de o distinguir no meio dos demais?
A artificialidade de uma inteligência que não nos entende
À medida que a inteligência artificial se foi instalando nos nossos dias, feita realidade firmada, o desejo de que as máquinas compreendessem os humanos tornou-se a prioridade maior. Apesar dos avanços da última década, muitas das promissoras aplicações que nos rodeiam estão mais ligadas a processos de automatização do que de compreensão. Mesmo que as respostas devolvidas sejam as corretas, quando perguntamos à Siri como vai estar o tempo amanhã ou usamos o assistente de voz para pesquisar algo no Google, isso não quer dizer que os dispositivos nos entendem, propriamente.
Sequências de execução de tarefas lógicas com o fim de resolver um determinado problema em computação, os algoritmos entram em ação. Mais do que uma expressão matemática complexa, os algoritmos funcionam como uma espécie de manual de instruções das operações que um computador deve executar até atingir o fim que desejamos. Operações e respetiva sequência - são um dos pilares das ciências da computação e já o eram muito antes de se assumirem protagonistas da revolução tecnológica dos últimos quinze anos. É certo que muito evoluíram desde os seus primórdios. Para Nick Polson e James Scott,[1] o que distingue os algoritmos de hoje dos de antigamente resume-se a dois pontos: o facto de se basearem em probabilidades e de serem treinados com dados. Conforme explicam, “o papel do programador já não é dizer ao algoritmo o que fazer. É dizer-lhe como se auto-treinar no que fazer, usando dados e as regras das probabilidades”. É com base em probabilidades que os corretores automáticos nos apresentam as suas sugestões ou que motores de busca ousam retorquir “não queria antes procurar por isto?”.
O processamento de linguagem natural é uma das aplicações mais entusiasmantes da inteligência artificial porque deixa em aberto o sonho inicial de que, um dia, pessoas e máquinas se compreendam num sentido mais orgânico. E, quiçá, mais humano.
Todos os idiomas do mundo não chegam para apanhar o inglês
Não obstante os progressos dos últimos anos, o processamento de linguagem natural é uma das áreas em que a divisão digital se faz notar com mais intensidade. Impulsionada pelas grandes tecnológicas americanas, a investigação parece seguir já em velocidade-cruzeiro no que diz respeito ao inglês, mas não é esse o caso para os restantes idiomas. É certo que uma boa parte das bibliotecas de software de código aberto utilizadas para processamento de linguagem natural já suporta português, mas o desempenho fica bastante aquém do da anglofonia. Lucas Sepeda, do Grupo Turing da Universidade de São Paulo, explica que mesmo tarefas relativamente básicas neste âmbito, como a codificação de palavras em números, não estão desenvolvidas para o nosso idioma - pelo menos, não de forma aberta e acessível.
O português não é caso único. Até idiomas ainda mais falados que o nosso, como o espanhol ou o francês, padecem do mesmo mal. No início de Julho, o LRE Map, uma ferramenta de pesquisa dedicada ao mapeamento de recursos linguísticos, listava 916 recursos em inglês (aos quais podemos adicionar 121 específicos do inglês americano). O idioma mais perto dessa marca era o alemão, mas com uns modestos 216 recursos. O português nem à casa das centenas chega. E se só olharmos para os recursos de livre acesso, nem metade disso totalizam (gráfico interativo).
Emily M. Bender, linguista e investigadora na área de linguística computacional na Universidade de Stanford, refere que a maior parte da pesquisa feita neste âmbito que não se foque no inglês acaba por ser relegada para segundo plano, muitas vezes rotulada como sendo “específica a um determinado idioma”.[2] Ao invés, a pesquisa feita com base no inglês muitas vezes nem sequer menciona o idioma nas publicações. O problema reflete-se na institucionalização do progresso feito em inglês como paradigma global. É, hoje, muito difícil perceber se os modelos utilizados para processamento de linguagem natural o são de facto, ou se são apenas modelos de processamento de inglês. Num mundo onde se falam mais de 7000 idiomas[3], será certamente limitado assumir que avanços significativos em apenas uma delas se convertam em conhecimento e utilização universais.
Falta, ainda, treinar os modelos com quantidades de texto suficientemente robustas para que daí se possam extrair padrões mais complexos, mais precisos, mais abrangentes. Uma vez que a digitalização de texto é fundamental, sendo o português uma das línguas mais utilizadas na internet, é seguro dizer que a nossa língua está bem equipada para essa fase do processo. Contudo, importa realçar a necessidade de diversidade nos vários corpos de texto disponíveis para esta etapa; possivelmente um dos calcanhares de Aquiles nesta conjuntura. Afinal, é muito diferente se analisarmos um diploma legal ou um texto literário, por exemplo.
A prevalência do português do Brasil sobre o europeu poderá representar um desafio extraordinário no que diz respeito a aplicações adequadas aos múltiplos contextos. Contudo, uma investigação recente que incluía uma comparação entre ambas as normas[4] denota que, pelo menos nalgumas tarefas (neste caso, a incorporação de palavras), os algoritmos disponíveis funcionam ligeiramente melhor com PT-BR do que com PT-EU. Ainda assim, em 2016, investigadores do NLX | Grupo da Fala e Linguagem Natural (Faculdade de Ciências da Universidade de Lisboa) avançaram que o treino de modelos com textos destas duas variantes de português se traduzia em resultados de maior precisão.[5]
Humanos ou máquinas, é difícil aprender uma língua. O léxico e a gramática servem de alicerces deste sistema complexo, mas são a fonética, a fonologia, a morfologia, a sintaxe, a semântica e a pragmática que assumem os papéis indispensáveis quando o analisamos.
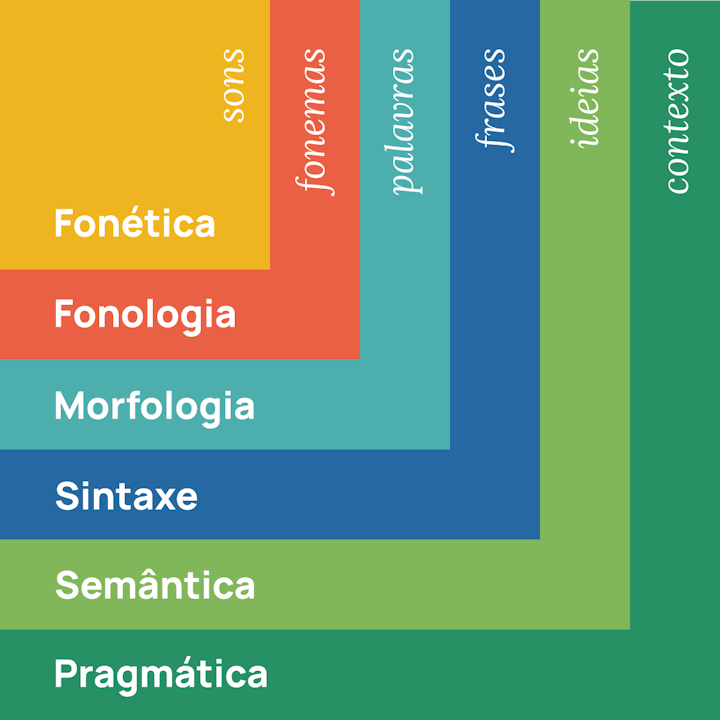
Níveis de análise linguística
Páginas como Very Nice Dictates Portuguese ilustram com humor a importância de cada uma destas dimensões, misturando traduções literais ou descontextualizadas com adaptações livres que incluem jogos de palavras e sons. Ainda que os tweets publicados estejam maioritariamente em inglês, a verdade é que só são compreensíveis se a pessoa também: 1) souber português e 2) conhecer a realidade cultural do nosso país. Ademais, sabemos que não é preciso uma expressão de gramática imaculada ou sotaques perfeitos para que se entenda o significado do que está a ser dito. No início deste ano, uma investigação conduzida na Universidade de Washington[6] acabou por receber várias críticas por trabalhar um corpo de texto que incluía muitas frases de “gramática dúbia”. Yejin Choi, professora associada que liderou o projecto, refutou as objecções, explicando que se os humanos conseguem lidar com esse tipo de situações (e interpretá-las correctamente em 94% dos casos), então as máquinas devem ser preparadas para atingir os mesmos resultados.
Literatura, IA e Classificação
Apesar das dificuldades, o processamento de linguagem natural tem utilizações práticas, sendo já utilizado com algum sucesso na classificação, sumarização e geração de textos. A classificação é, pois, o que nos interessa para este caso, uma vez que pretendemos diferenciar a obra poética de Fernando Pessoa.
Uma das experiências mais recentes na classificação de autores de textos literários tornou plausível a teoria de que a peça “Henrique VIII”, de William Shakespeare, é uma obra colaborativa. Recorrendo à utilização de máquinas de vetores de suporte e a técnicas como estilometria contínua,[7] Petr Plecháč, da Academia de Ciências Checa, conseguiu demarcar quais as passagens que terão sido escritas pelo famoso dramaturgo inglês e quais as que tiveram a mão de John Fletcher.[8]
O fascínio pelos textos de Fernando Pessoa e pela sua heteronímia enquanto modelos de treino para modelos de PLN não é novo. Neste contexto, o facto de ter uma obra extensa, que se desdobra em múltiplas personalidades literárias, torna-o particularmente aliciante. Da escolha lexical à estrutura formal dos textos, é clara a diferenciação entre a poesia de cada um dos heterónimos com base nas suas características. Em 2015, um primeiro ensaio, de João F. Teixeira e Marco Couto, provava que a classificação automática dos textos de Ricardo Reis e de Álvaro de Campos era possível. Já este ano, do outro lado do Atlântico, o Grupo Turing - um grupo de estudo interdisciplinar da Universidade de São Paulo dedicado à inteligência artificial - expandiu a experiência. Através de aprendizagem automatizada, os investigadores diferenciaram a obra dos heterónimos mais conhecidos.
SVM, Companhia & LDA - Os Acrónimos da Técnica
Antes de serem aplicados quaisquer modelos, o texto tem de ser pré-processado. Isto significa que deve passar por uma série de etapas que vão facilitar o objectivo final de classificação. Depois desses primeiros estágios, Teixeira e Couto optaram por testar várias métricas de ocorrência de termos, na busca daquela que lhes daria maior precisão. O Grupo Turing apostou apenas na criação de uma matriz frequência do termo–inverso da frequência nos documentos. Confusos? Esta matriz divide o número de vezes que um termo surge num determinado texto (term frequency) pelo número de textos em que aparece (inverse document frequency). Deste modo, se um termo aparece muitas vezes em múltiplos textos, acaba por perder a importância. Por oposição, se um termo aparece sempre no mesmo tipo de textos, então, assume-se que é relevante dentro daquela tipologia.
No artigo, a equipa portuguesa afirma ter atingido uma taxa de sucesso de 97%, depois de submeter a tal matriz a máquinas de vectores de suporte (do inglês, support vector machine, SVM) - um conjunto de métodos de aprendizagem automatizada supervisionada. Apesar das limitações, nomeadamente aos níveis de eficiência computacional e de sobreajuste, este modelo tende a apresentar resultados bastante positivos na classificação de documentos, sobretudo em conjuntos de dados que não sejam particularmente extensos. Depois de serem “treinadas”, estas máquinas atribuem uma determinada categoria a cada entrada, representando-as como pontos no espaço e definindo o hiperplano que as separa.
O Grupo Turing também utilizou SVM na sua abordagem, mas não só. Além dela, explorou o modelo NaiveBayes, que é basicamente a aplicação do teorema de Bayes. A fórmula determina a probabilidade de um determinado evento acontecer com base no conhecimento de condições que podem influenciar a sua ocorrência. Por exemplo, a probabilidade de tirarmos um Ás de Copas de um baralho de cartas, sabendo que acabámos de tirar um Ás de Espadas. No final, as probabilidades condicionadas acabaram por revelar-se menos precisas: esse modelo obteve resultados positivos na ordem dos 60.90%, já com SVM esse número aumentou para 82.71%.
No Interruptor, explorámos um outro modelo para classificação de texto, a alocação de Dirichlet latente (do inglês, Latent Dirichlet Allocation, LDA). Este modelo constrói-se sobre a distribuição de Dirichlet. Grosso modo, é assumido que cada texto tem uma mistura de tópicos relevantes, unidos por palavras que estão próximas umas das outras do ponto de vista semântico - se o mesmo par de palavras aparece em mais do que um texto, depreende-se que faz parte da mesma unidade semântica. Ou seja, a diferenciação entre heterónimos, neste caso, fez-se com base na distinção entre tópicos abordados. Apesar de ter sido posto à prova com algum sucesso na classificação de textos literários, nomeadamente prosa e dramaturgia, a aplicação do LDA à poesia permanecia pouco conclusiva até 2018, altura em que Navarro-Colorado o empregou na análise de mais de cinco mil sonetos da “Era de Ouro Espanhola” (séculos XVI e XVII).[9] Já este ano, Plecháč fez uso deste modelo para a visualização de tendências de tópicos na comparação de corpus de poesia em checo, russo, alemão e inglês.[10]
Na maior parte dos testes que realizámos, já na versão final, a marca de coerência (a métrica que determina o sucesso da aplicação do LDA) rondou os 49%, com máximos de 53% e mínimos de 47%. A quantidade de texto influenciou substancialmente o resultado. Inicialmente, a nossa análise incidia sobre a poesia dos heterónimos mais conhecidos e do ortónimo. Contudo, a bitola era demasiado frágil e acabámos por incluir também o Bernardo Soares e a prosa de Fernando Pessoa. De facto, os resultados denunciaram uma das insuficiências conhecidas do LDA: a sua diminuída eficácia quando aplicado a textos curtos, caso de grande parte dos poemas analisados. No entanto, com a entrada da prosa no objeto de análise, tornou-se evidente que o modelo é capaz de diferenciar os tópicos, embora nem sempre seja claro se a cada um deles corresponde um heterónimo específico. Em baixo, uma amostra dos resultados, com as palavras mais salientes em vários tópicos (gráfico interativo). Destes, só um não corresponde a textos de Fernando Pessoa em nome próprio.
O homem sonha, a obra nasce
O que aí vem é muito maior, contudo. As redes neuronais oferecem possibilidades muito mais avançadas no que respeita à classificação de texto. Estas redes conseguem diferenciar contextos (ainda que não os entendam, necessariamente) tornando obsoletas algumas das vertentes do pré-processamento usado nos exemplos acima. Mais complexas e ainda em amplo desenvolvimento, apesar de estarem já funcionais para algumas tarefas, estas redes apresentam algumas vulnerabilidades, como o risco de sobreajuste de dimensões, ou instabilidade quando treinadas com textos contraditórios.
Os mais recentes desenvolvimentos do GPT-3, um modelo de inteligência artificial que opera sobre o maior conjunto de dados linguísticos disponível atualmente, levantam o véu das promessas infinitas. Focado na geração de texto, consegue proezas como reescrever um texto num estilo completamente diferente, responder a questões médicas ou escrever publicações virais para um blogue falso. Contudo, a equipa por trás do modelo salienta que a escolha de exemplos de sucesso não deve ofuscar as falhas da tecnologia, que errou numa questão tão simples como o número que antecede um milhão.
Para já, não existem modelos perfeitos de processamento de linguagem natural. No caso do português, grande parte da caminhada ainda está por fazer, mas seguimos a passos largos rumo a um futuro em que as máquinas serão capazes de mais e de melhor, também no nosso idioma. Por agora, a tarefa que lhes foi confiada está concluída: um algoritmo consegue distinguir os heterónimos de Pessoa. Mas estão longe de o perceberem como nós.
O código desenvolvido para este projeto está aberto e disponível no GitHub do Interruptor.
